
{kind=link}
Ever wondered why some websites rank high in search results while others remain hidden in the digital abyss? The answer often comes down to two fundamental concepts in technical SEO: crawlability and indexability. Without these foundational elements properly configured, even the most valuable content may never appear in search results.
In this second installment of our technical SEO series, we’re diving deep into how search engines discover, process, and ultimately display your web pages to potential visitors. If Part 1 laid the groundwork with site performance and mobile responsiveness, Part 2 reveals the technical mechanisms that ensure search engines can effectively access and understand your content.
Introduction to Technical SEO Part 2
Why Crawlability & Indexability Matter
Crawlability and indexability function as the gatekeepers to search visibility. If search engines can’t crawl your site efficiently, they can’t discover your content. If they can’t index your pages properly, users won’t find you when they search for relevant terms.
According to a study by Ahrefs, a surprising 40% of webpages aren’t indexed by Google at all. This means millions of pages exist online that never appear in search results—often due to preventable technical issues.
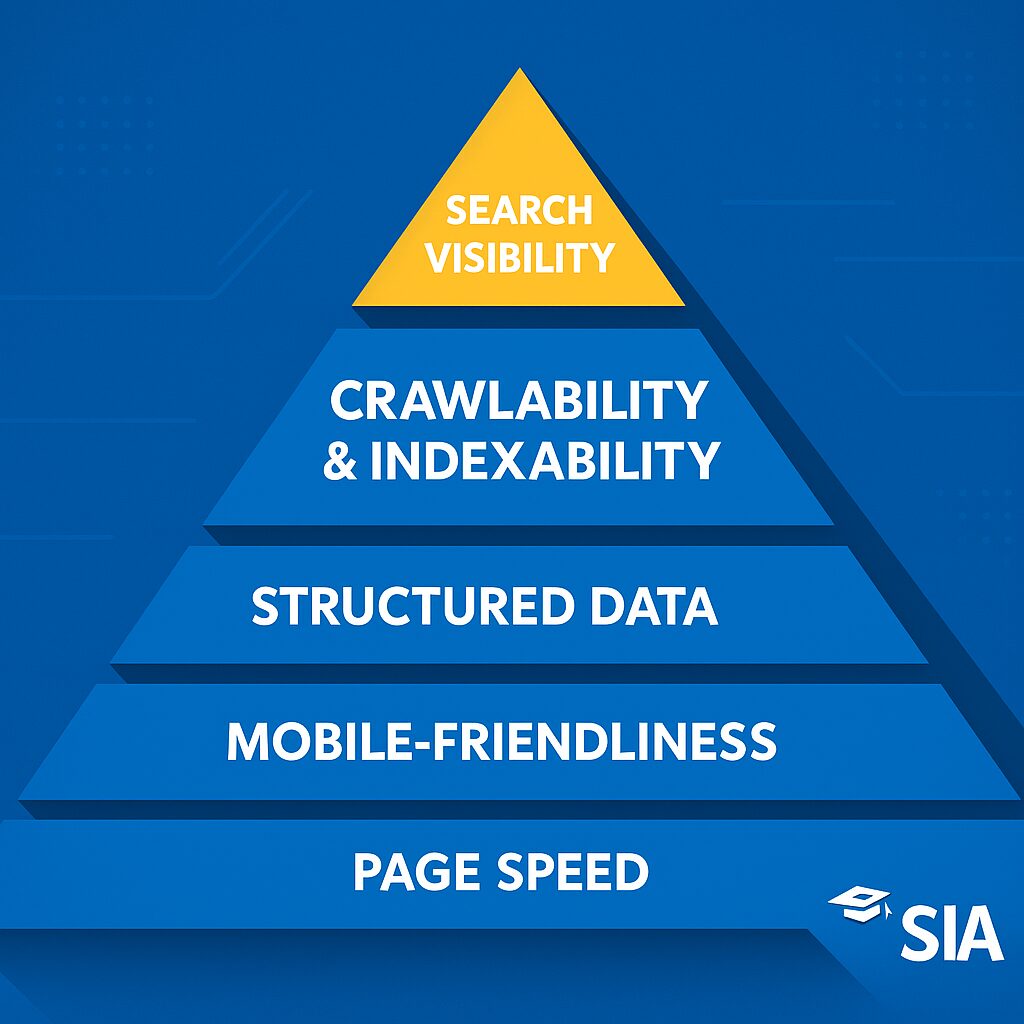
Recap of Key Concepts from Part 1
In our previous article, we covered the essentials of technical SEO fundamentals:
- Page speed optimization
- Mobile-friendliness
- Secure connections (HTTPS)
- Structured data implementation
These elements create the perfect environment for effective crawling and indexing. A fast, secure, and well-structured site gives search engines the optimal conditions to discover and process your content.
Understanding Crawlability
What Is Crawlability in SEO?
Crawlability refers to how easily search engine bots can navigate through your website and discover all your content. Technically speaking, this involves server response codes, HTML structure, and network of links that bots follow.
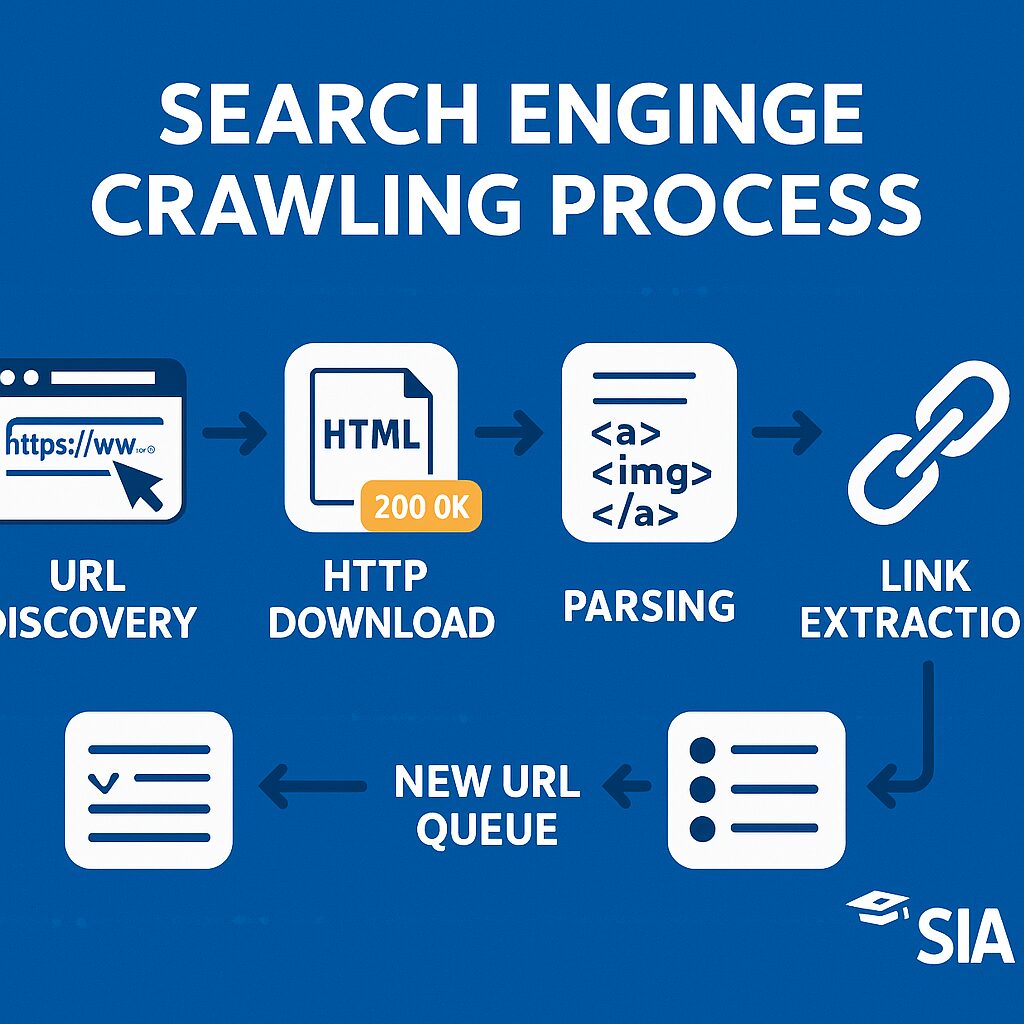
Google’s documentation explains that Googlebot follows a process called URL discovery, where it finds pages through:
- Links from previously crawled pages
- Sitemaps submitted to Search Console
- URL submission tools
When examining your server logs, you’ll see Googlebot requests appear with the user-agent string:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)What Is Crawling in SEO?
Crawling is the technical process where search engine bots systematically request URLs, download HTML content, and follow links to discover new pages. This process consumes server resources, which is why search engines allocate a limited “crawl budget” to each domain.
During crawling, bots parse your HTML, looking at elements like:
- Page title (
<title>tag) - Headings (
<h1>,<h2>, etc.) - Main content (
<article>,<main>, etc.) - Navigation elements (
<nav>) - Internal and external links (
<a href>)
The Role of Search Engine Bots
Search engine bots are sophisticated programs that handle several technical tasks:
- HTTP request handling for content retrieval
- HTML parsing and rendering
- JavaScript execution (though with limitations)
- Image and resource processing
- Link extraction and prioritization
Modern crawlers like Googlebot are now based on Chrome and can render most JavaScript. You can test this using Google Search Console’s URL Inspection tool, which shows you exactly how Googlebot sees your page.
Common Factors Affecting Crawlability
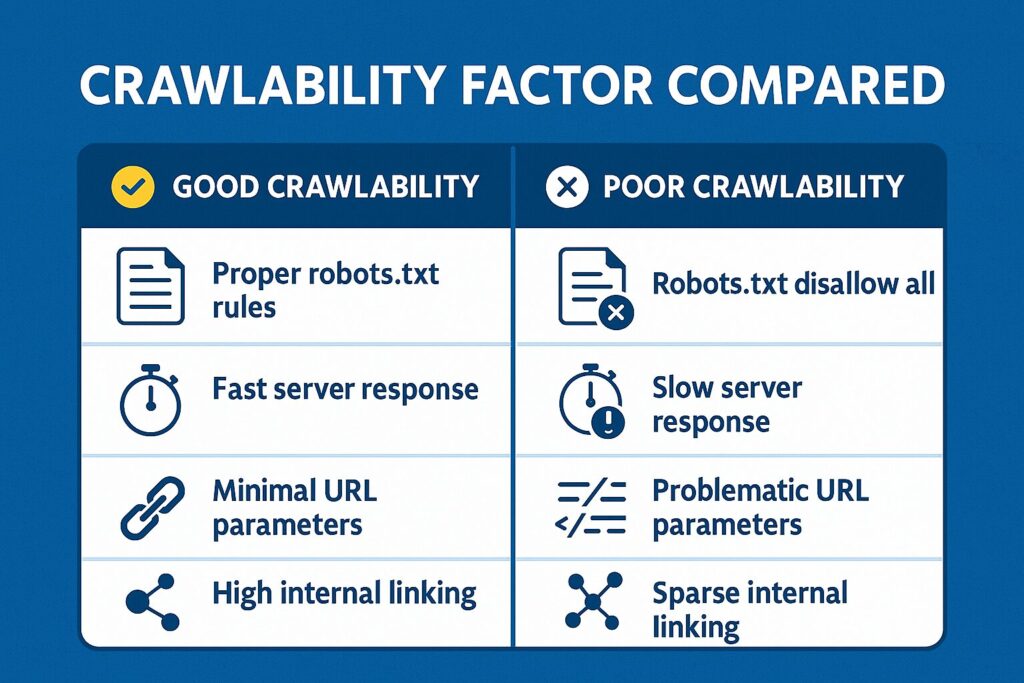
Several technical issues can hamper your site’s crawlability:
Robots.txt configuration issues: A poorly configured robots.txt file can accidentally block important content:
# This blocks all crawlers from accessing your CSS files
User-agent: *
Disallow: /css/
# Better approach - allow CSS for proper rendering
User-agent: *
Allow: /css/Server response codes: Codes other than 200 can impact crawling:
- 301/302 redirects slow down crawling and consume budget
- 404 errors terminate crawling paths
- 5xx server errors prevent content from being discovered
- Slow response times (>2 seconds) can reduce crawl frequency
URL parameter handling: E-commerce and filtering parameters can create infinite URL spaces:
# Examples of problematic URL patterns
example.com/products?sort=price&color=red&size=medium&view=grid
example.com/products?color=red&sort=price&size=medium&view=gridWithout proper parameter handling, these variations create duplicate content issues.
Difference Between Crawling and Indexing
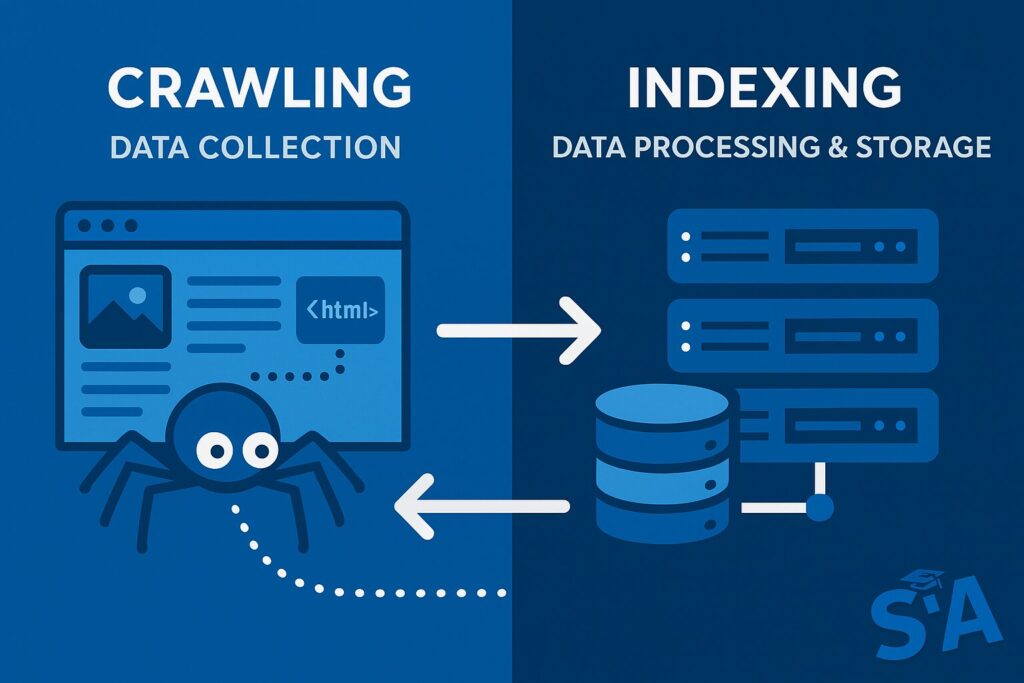
Why Both Processes Are Crucial
From a technical perspective, crawling and indexing represent two distinct phases in search engine processing:
- Crawling: The data collection phase (HTTP requests and content retrieval)
- Indexing: The data processing and storage phase (parsing, analyzing, and storing in the search index)
A page must successfully pass through both phases to be eligible for ranking in search results.
What Is Indexing in SEO?
Indexing involves complex algorithms that:
- Parse the HTML structure
- Extract text content
- Analyze semantics and context
- Identify entities and relationships
- Store the processed data in inverted indices
This process creates searchable entries that match user queries with relevant content. Google’s index is estimated to be hundreds of petabytes in size, with specialized data structures optimized for retrieval speed.
Overcoming Indexing Roadblocks
Common technical barriers that prevent indexing include:
Improper meta directives: The noindex directive explicitly tells search engines not to index a page:
<!-- This page won't be indexed -->
<meta name="robots" content="noindex">
<!-- This blocks only Google, but allows other search engines -->
<meta name="googlebot" content="noindex">X-Robots-Tag HTTP header: This server-side approach achieves the same result:
HTTP/1.1 200 OK
X-Robots-Tag: noindexCanonical conflicts: Contradictory signals confuse search engines:
<!-- Contradictory signals -->
<meta name="robots" content="noindex">
<link rel="canonical" href="https://example.com/page/" />Real-World Examples
A large e-commerce site discovered that their faceted navigation was creating millions of URLs with parameter combinations. By implementing technical solutions like:
<!-- On filtered pages -->
<link rel="canonical" href="https://example.com/main-category/" />And proper parameter handling in Google Search Console, they reduced their indexed URLs by 60% while increasing the crawl frequency of important product pages.
Conducting a Crawlability Test
Recommended Tools & Techniques
To properly assess crawlability, use these technical approaches:
Server log analysis: Examine how search engines are actually crawling your site:
93.184.216.34 - - [12/Dec/2022:15:14:39 +0000] "GET /example.html HTTP/1.1" 200 1234 "https://example.com/" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"This log entry shows:
- IP address (can be verified against Google’s IP ranges)
- Request timestamp
- Requested URL
- HTTP status code (200)
- Referrer URL
- User agent string
Crawl tools configuration: When setting up Screaming Frog or similar tools, customize them to detect technical issues:
# Custom extraction of hreflang attributes
//link[@rel='alternate' and @hreflang]/@hreflang
# Finding uncrawlable JavaScript links
//a[starts-with(@href, 'javascript:')]/@hrefHow to Interpret Crawl Reports
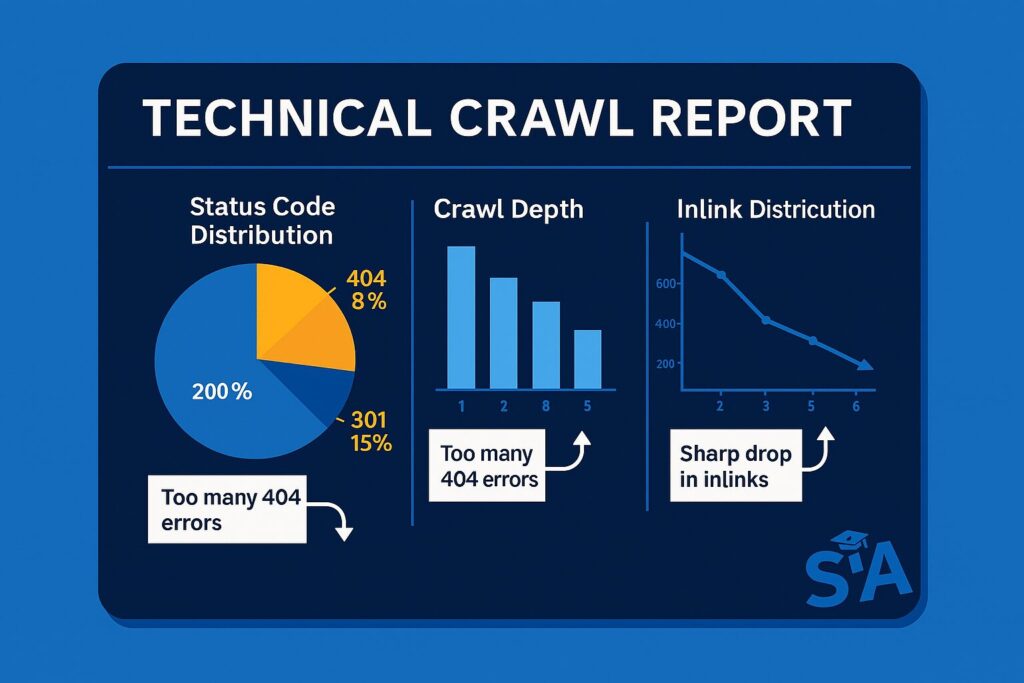
Technically relevant metrics to analyze in crawl reports:
Status code distribution:
- High percentage of 301/302 redirects indicates inefficient link structures
- Any 5xx errors require immediate attention
- Large numbers of 404s suggest broken internal linking
Crawl depth analysis:
Depth 0: Homepage (1 URL)
Depth 1: Main category pages (8 URLs)
Depth 2: Subcategory pages (64 URLs)
Depth 3: Product pages (512 URLs)
Depth 4+: Orphaned content (126 URLs)Pages at depth 4+ often receive less frequent crawling.
Inlink distribution: URLs with fewer than 3 internal links pointing to them are often under-crawled.
Quick Fixes for Common Issues
Implementation of technical fixes:
Fixing redirect chains:
Before:
example.com/old-page/ → example.com/intermediate/ → example.com/new-page/After:
example.com/old-page/ → example.com/new-page/Adding missing directives:
<!-- For paginated content -->
<link rel="next" href="https://example.com/blog/page/2/">
<!-- For multilingual content -->
<link rel="alternate" hreflang="es" href="https://example.com/es/page/">FAQs: “How Do I Do a Crawlability Test?”
A technical approach to crawlability testing involves:
- Configure a crawler with settings that match search engine behavior:
# Screaming Frog configuration User-Agent: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) Respect robots.txt: Yes Render JavaScript: Yes - Analyze server response headers for directives that might block crawling:
HTTP/1.1 200 OK Cache-Control: max-age=3600 X-Robots-Tag: noindex, follow Content-Type: text/html; charset=UTF-8 - Export and categorize issues by technical impact and difficulty to fix
Best Practices to Improve Crawlability
Streamlining Site Architecture
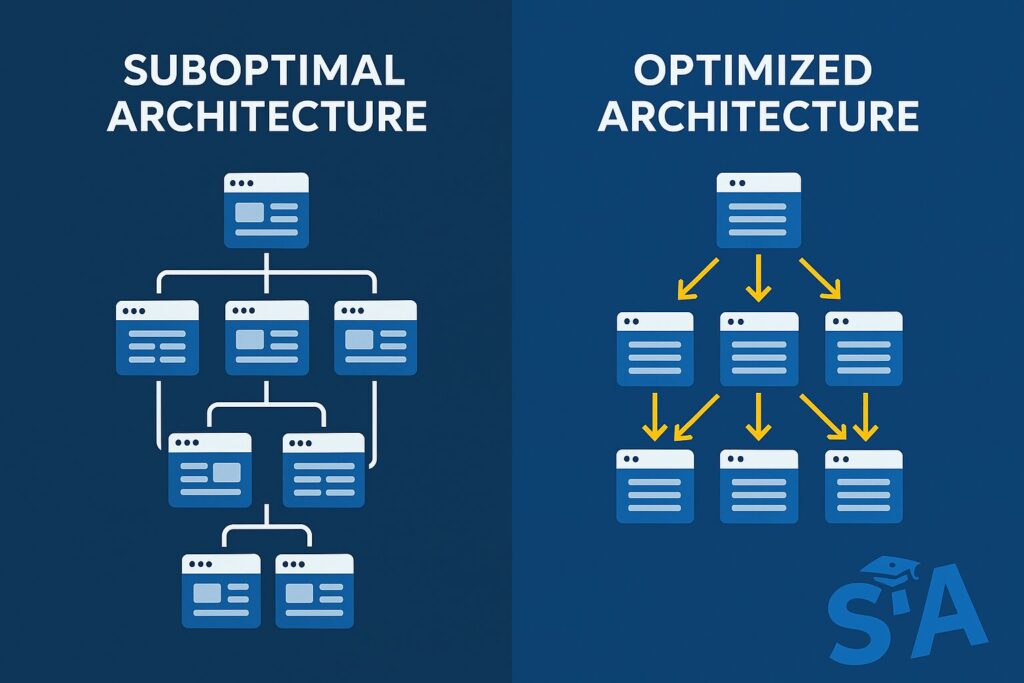
Technical implementation of effective site architecture:
Interlinking depth optimization:
<!-- Homepage HTML -->
<nav>
<a href="/category1/">Category 1</a>
<a href="/category2/">Category 2</a>
</nav>
<!-- Category page HTML -->
<div class="subcategories">
<a href="/category1/subcategory1/">Subcategory 1</a>
<a href="/category1/subcategory2/">Subcategory 2</a>
</div>URL structure optimization:
# Good URL structure
https://example.com/category/subcategory/product-name/
# Problematic URL structure
https://example.com/p/?id=12345&cat=789Effective Internal Linking Strategies
Technical implementation of internal linking:
HTML implementation of contextual links:
<p>Learn more about our <a href="/services/seo-optimization/">technical SEO services</a> to improve your site's performance.</p>Programmatic related content links:
<?php
// Pseudocode for dynamic related content linking
$related_posts = get_posts_in_same_category($current_post, 3);
foreach($related_posts as $post) {
echo '<a href="' . $post->permalink . '">' . $post->title . '</a>';
}
?>Importance of XML Sitemaps
Technical aspects of sitemap implementation:
Basic XML sitemap structure:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>https://example.com/</loc>
<lastmod>2023-04-06T12:32:18+00:00</lastmod>
<changefreq>daily</changefreq>
<priority>1.0</priority>
</url>
</urlset>Sitemap index for large sites:
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<sitemap>
<loc>https://example.com/sitemap-products.xml</loc>
<lastmod>2023-04-06T12:32:18+00:00</lastmod>
</sitemap>
<sitemap>
<loc>https://example.com/sitemap-categories.xml</loc>
<lastmod>2023-04-05T10:15:24+00:00</lastmod>
</sitemap>
</sitemapindex>Avoiding Crawl Blockers (Robots.txt & More)
Technical implementation of proper robots rules:
Effective robots.txt configuration:
User-agent: *
Disallow: /wp-admin/
Disallow: /checkout/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://example.com/sitemap_index.xmlHTTP response headers for non-HTML content:
# For PDF files that shouldn't be indexed
HTTP/1.1 200 OK
Content-Type: application/pdf
X-Robots-Tag: noindex, followEnhancing Indexability
Meta Tags and Their Role

Technical implementation of key meta tags:
Title and meta description:
<title>Technical SEO Guide: Crawlability & Indexability | Example.com</title>
<meta name="description" content="Learn how to improve your site's crawlability and indexability with our comprehensive technical SEO guide.">Social media tags:
<meta property="og:title" content="Technical SEO Guide: Crawlability & Indexability">
<meta property="og:description" content="Learn how to improve your site's crawlability and indexability with our comprehensive technical SEO guide.">
<meta property="og:image" content="https://example.com/images/technical-seo-guide.jpg">
<meta property="og:url" content="https://example.com/technical-seo-guide/">Dealing with Duplicate Content
Technical solutions for duplicate content:
Canonical tag implementation:
<!-- On the preferred version of the page -->
<link rel="canonical" href="https://example.com/original-post/">
<!-- On duplicate versions -->
<link rel="canonical" href="https://example.com/original-post/">Parameter handling via robots.txt:
# Instruct crawlers not to use specific parameters
User-agent: *
Disallow: /*?sort=
Disallow: /*?view=Canonical Tags and Robots Directives
Technical implementation details:
Self-referencing canonicals:
<!-- Good practice to include on all pages -->
<link rel="canonical" href="https://example.com/current-page/">Pagination with canonicals and next/prev:
<!-- On page 2 of a series -->
<link rel="canonical" href="https://example.com/article/page/2/">
<link rel="prev" href="https://example.com/article/">
<link rel="next" href="https://example.com/article/page/3/">Leveraging IndexNow for Faster Indexing
Technical implementation of IndexNow:
API endpoint request:
https://www.bing.com/indexnow?url=https://example.com/new-page/&key=your_key_hereBulk URL submission:
{
"host": "example.com",
"key": "your_key_here",
"urlList": [
"https://example.com/new-page1/",
"https://example.com/updated-page2/",
"https://example.com/new-product/"
]
}Verification file setup:
# Place a text file at your domain root
https://example.com/your_key_here.txtAdvanced Technical SEO Considerations
Understanding Crawl Budget
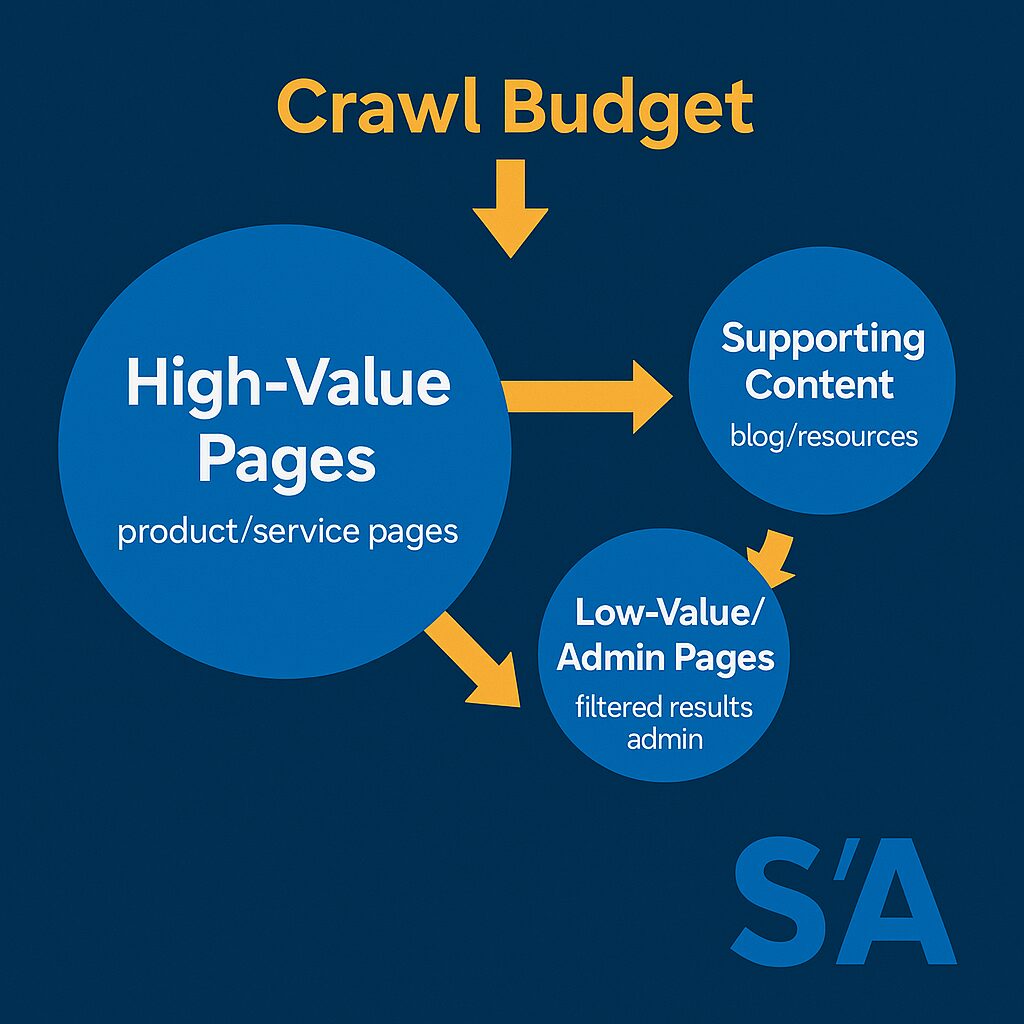
Technical aspects of crawl budget optimization:
Server log crawl frequency analysis:
# Extract Googlebot requests per hour
grep -i googlebot access.log | awk '{print $4}' | cut -d: -f1,2 | sort | uniq -cIdentifying crawl waste:
# Find URLs with high crawl frequency but low value
grep -i googlebot access.log | grep "sort=" | wc -lMobile-First and Other Evolving Algorithms
Technical implementation for mobile-first indexing:
Responsive design implementation:
<meta name="viewport" content="width=device-width, initial-scale=1.0">Ensuring identical content across versions:
<!-- Both mobile and desktop should have the same primary content -->
<main>
<h1>Primary content heading</h1>
<p>This content must be identical on mobile and desktop versions.</p>
</main>Strategies from Advanced Technical SEO
Technical implementation of advanced concepts:
Implementing structured data for rich results:
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Crawlability and Indexability: Technical SEO Guide",
"author": {
"@type": "Person",
"name": "SEO Expert"
},
"datePublished": "2023-04-06T12:00:00+00:00",
"image": "https://example.com/images/technical-seo.jpg"
}
</script>JavaScript rendering optimization:
<!-- Using dynamic rendering or prerendering for JS-heavy sites -->
<script>
// Load critical content without JavaScript first
document.addEventListener('DOMContentLoaded', function() {
// Then load enhanced features
loadEnhancedFeatures();
});
</script>Practical Technical SEO Implementation
Technical monitoring implementations:
Automated crawl alert system:
# Pseudocode for crawl monitoring
def check_indexing_status():
urls = get_important_urls()
for url in urls:
status = check_google_index(url)
if status != "indexed":
send_alert(f"Indexing issue detected for {url}")Server response monitoring:
# Shell script to check for 5xx errors
curl -I https://example.com/important-page/ | grep "HTTP/"
# Should return HTTP/1.1 200 OKTechnical SEO Training & Resources
Signing Up for a Technical SEO Course
Technical topics covered in comprehensive courses:
- HTTP protocol fundamentals
- Server response code analysis
- Log file parsing and analysis
- JavaScript rendering for SEO
- Schema.org implementation
- Site migration planning
SEO Training Course by Moz
Technical modules typically include:
- Crawl efficiency analysis
- Server-side rendering vs. client-side rendering
- Implementation of hreflang for international sites
- XML sitemap optimization
- Structured data validation
Exploring Technical SEO Resources
Technical documentation and tools:
Google’s official resources:
Technical auditing tools:
Free and Premium SEO Learning Options
Technical skills emphasized in modern SEO training:
- HTTP header analysis
- Regular expression use for pattern matching
- Basic Python/R for data analysis
- API integration for automation
- Chrome DevTools for debugging
Frequently Asked Questions
What Is Crawlability in SEO? (Revisited)
From a technical perspective, crawlability depends on:
- Server response times (<200ms is ideal)
- Clean URL structures without parameters that create loops
- Proper implementation of robots.txt directives
- Efficient internal linking that limits crawl depth
What Is Indexing in SEO? (Revisited)
Technical aspects that influence indexing:
- Proper HTTP status codes (200 for indexable content)
- Correct implementation of indexing directives:
<!-- Allow indexing --> <meta name="robots" content="index, follow"> <!-- Prevent indexing --> <meta name="robots" content="noindex, follow"> - Clear canonicalization signals
Difference Between Crawling and Indexing (Revisited)
Technical distinction in server interactions:
Crawling involves:
- HTTP GET requests from search engine IPs
- Downloading HTML, CSS, JavaScript
- Following links to discover content
Indexing involves:
- Processing and storing discoverable content
- Analyzing relationships between pages
- Creating searchable entries in the search index
How to Fix Crawl & Indexing Errors
Technical implementation of common fixes:
Fixing server errors:
# Check for 5xx errors in logs
grep " 5[0-9][0-9] " access.log | cut -d" " -f7 | sort | uniq -cImplementing proper redirects:
# .htaccess implementation for Apache
Redirect 301 /old-page.html https://example.com/new-page/Fixing orphaned content:
-- SQL query to find pages without inlinks (pseudocode)
SELECT url FROM pages WHERE inlink_count = 0;Conclusion
Key Takeaways for Crawlability & Indexability
Technical success factors include:
- Server response time optimization (<200ms)
- Clean information architecture (max 3 clicks from homepage)
- Proper implementation of technical directives
- Regular monitoring of crawl and index status
Next Steps in Your Technical SEO Journey
Technical next steps to implement:
- Set up automated crawl monitoring
- Configure server log analysis
- Implement structured data for important content types
- Create a technical SEO test environment
Ongoing Education: Technical SEO Training & Courses
Stay updated on technical developments:
- Core Web Vitals thresholds and measurement
- New structured data types
- Changes to JavaScript rendering capabilities
- Advancements in natural language processing
Building a Long-Term Strategy for Success
Technical implementation plan:
1. Weekly: Monitor server logs for crawl patterns
2. Monthly: Full technical audit with crawl tools
3. Quarterly: In-depth indexing analysis
4. Biannually: Technical stack review and updates